Introduction
Smart Data Lake Builder (SDLB for short) is an automation framework that makes loading and transforming data a breeze. It can be used to create data pipelines for a wide range of use cases such as Lakehouse, Data Products and Data Mesh.
SDLB is implemented in Java/Scala and builds on top of open-source big data technologies like Apache Hadoop and Apache Spark, including connectors for diverse data sources (HadoopFS, Hive, DeltaLake, JDBC, Splunk, Webservice, SFTP, Kafka, JMS, Excel, Access) and file formats.
Benefits of Smart Data Lake Builder
- Cost-effective implementation of data pipelines
- Increased productivity of data scientists
- Higher level of self-service
- Decreased operations and maintenance costs
- Fully open source, no vendor lock-in
When should you consider using Smart Data Lake Builder ?
Some common use cases include:
- Building Lakehouse architecture - drastically increasing productivity and usability
- Implementing Data Products - building simple and complex data apps in a Data Mesh approach
- DWH automation - reading and writing to relational databases via SQL
- Data migration - efficiently create one-time data pipelines
- Data Catalog / Data Lineage - generated automatically from metadata and code
See Features for a comprehensive list of SDLB features.
How it works
The following diagram shows the core concepts:
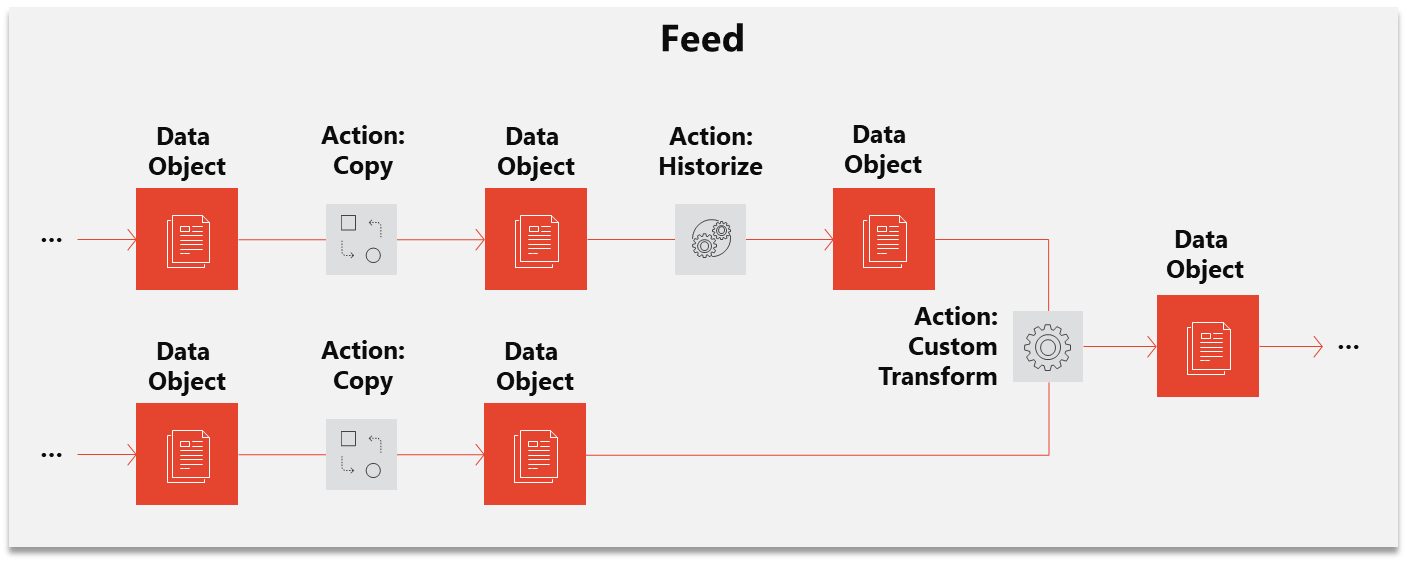
Data object
A data object defines the location and format of data. Some data objects require a connection to access remote data (e.g. a database connection).
Action
The "data processors" are called actions. An action requires at least one input and output data object. An action reads the data from the input data object, processes and writes it to the output data object. Many actions are predefined e.g. transform data from json to csv but you can also define your custom transformer action.
Feed
Actions connect different Data Object and implicitly define a directed acyclic graph, as they model the dependencies needed to fill a Data Object. This automatically generated, arbitrary complex data flow can be divided up into Feed's (subgraphs) for execution and monitoring.
Configuration
All metadata i.e. connections, data objects and actions are defined in a central configuration file, usually called application.conf. The file format used is HOCON which makes it easy to edit.
Getting Started
To see how all this works in action, head over to the Getting Started Guide page.
Get in touch
If you have issues, comments or feedback, please see Contributing on how to get in touch.
Commercial Support
If you are looking for commercial support, please contact us at smartdatalake@elca.ch to receive further information about subscription models.
Major Contributors
![]()
www.sbb.ch : Provided the previously developed software as a foundation for the open source project

www.elca.ch : Did the comprehensive revision and provision as open source project